- HOME >
- 専門家による技術解説 >
- 3次元化に向けて加速する半導体実装技術
3次元化に向けて加速する半導体実装技術
2025.01.14
3次元化に向けて加速する半導体実装技術
― 2.5D/3D実装・チップレット・ヘテロジニアス集積の最前線 ―
1. モノリシック集積の限界と半導体実装技術の進化
混成集積回路という用語を学生時代に習った覚えがある。ハイブリッド集積回路の和訳で、トランジスタやダイオードといった半導体素子と抵抗,キャパシタ,インダクタなどの受動素子を基板に実装し、配線で接続して所望の機能を実現する。これに相対する用語がモノリシック集積回路で、上記の素子をシリコン基板(チップ)上に、ウェハプロセスで集積化したものである。集積回路の歴史は、モノリシック集積回路の大規模化、つまり1つのシリコンチップにより多くのトランジスタや受動素子を集積化していくものであった。指導原理がムーアの法則と呼ばれているもので、毎年あるいは2年で搭載素子数が2倍になるというものであった。これを支えていたものがスケーリング則で、トランジスタを小さくする(微細化する)ほど、集積密度が上がるのは当然として、さらに消費電力は下がり、動作速度は増し、複雑な機能が実現できるといった、良いことずくめの半導体の特性(物理法則)であった。一つのシステムをワンチップで実現するSoC(System on a Chip)を目指していた。
しかし、その指導原理もそろそろ限界に達するのではないかと言われている。実は半導体の限界論は今までに(50年ぐらい前から)何回も言われて来た歴史があり、「またですか?」とオオカミ少年を見るような眼差しを向ける方もいるかもしれない。「今度こそ本物ですよ」。
微細化に伴い順調に動作速度を向上させていたが、2005年頃を境に動作速度は飽和(クロック周波数約4GHz)してしまっている。微細化も2030年頃に限界に達すると予想されている。頼みの綱は垂直方法にトランジスタを積層する3次元集積化で、NANDフラッシュメモリは2015年にこの方向に舵を切っている。設計およびビジネスの観点からも、これ以上の大規模なモノリシック集積のリスクが指摘されている。規模が大きくなり過ぎると、設計のやり直しのための時間と費用が耐えられなくなっている。実績のあるチップを組み合わせて、これをタイルのようインターポーザ上に並べて接続するチップレット方式の方が開発のスピードアップとなる。2.5次元実装と呼ばれている方式である。どうせなら3次元に縦積み実装(3次元実装)した方がフットプリントを縮小できる、といった流れである。そもそも、ロジック,メモリ,インターフェイス,光,RF,パワーなどはウェハ製造技術が異なるし、シリコン以外の半導体材料(InPやGaNなど)を使うことから、モノリシック集積を指向することに無理があるとする、ヘテロジニアス実装への流れである。
かつてハイブリッド実装製品と言えば、少量のニッチ製品といった印象すらあった。今日の2.5D/3D実装は、AI用半導体GPUをターゲットとしている。まさに最先端大量生産部品である。半導体ウェハ製造技術を流用し、微細で高密度の配線を実現している。そのため、最先端のLSI開発を行っているTSMCやIntel,Samsungが開発の中心的な役割を果たしている。その裏にはNVIDIAやAMD,QualcommなどのファブレスIC企業群がいる。ラピダスも前工程と3D実装などの後工程を一貫製造する予定である。
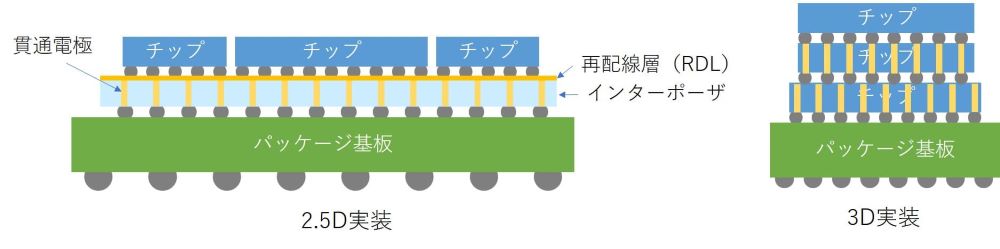
図. 2.5次元および3次元実装技術
2. GPU性能を引き上げる2.5D実装とチップレット
NVIDIAの最新GPU(Blackwell)は、2つのチップ(TSMCの4NP技術:4nmプロセス改良版で製造)をSiインターポーザ上で接続して実現している。GPU性能はFP8で20PFOPSであり、チップ間の接続伝送容量は10TB/sに達する。前の世代のGPUであるH100(1チップ)は集積密度がさほど変わらないTSMCの4N技術で製造していたことを考えると、2チップを2.5D実装することで、GPUとしての性能を約2倍にしたと言える。激しい開発競争の中で、設計の時間を短縮し、かつウェハプロセス上のリスクを最小に抑えた「解」であると言える。なお、その横に3次元DRAMであるHBM 8基(192GB)をインターポーザ上に搭載し、8TB/sの容量でGPUチップに接続されている。外部とは1.8TB/s(双方向)の高速インターフェイスNVLinkで接続される。消費電量は1.2kWに達するため、H100の空冷から水冷に変更している。
Siインターポーザによる実装もTSMCが手掛けている。また、TSMCはSiに替わり、再配線層(RDL)のみを用いたRDLインターポーザの技術も保有している。HBMとの信号線当たりの接続速度は8.6Gbpsであり、伝送密度に換算すると5Tbps/mmとなる。
Intelはインターポーザとして、有機基板をベースとし、高密度の接続が必要な部分にのみSiを埋め込んだSiブリッジを用いるEMIB(Embedded Multi-die Interconnect Bridge)を採用している。
インターポーザの下のパッケージ基板についても改善が進められている。現在の有機コア基板では、ドリルで機械的に貫通電極を形成するため、寸法が大きく、配線の高密度化が図れないとの問題がある。また、搭載されるSiチップとの熱膨張係数の差異が大きく、熱応力による破損が懸念され、パッケージサイズを大きくできないとの限界も指摘されている。レーザー加工などにより貫通電極径を小さくでき、かつ熱膨張係数の調整が可能で、薄層化もできるガラスコア基板の開発が進められている。
とにかく計算能力とメモリ容量ハングリーな生成AIの需要に応えるためには、できるだけ多くの計算リソースとメモリを同一パッケージに詰め込む必要がある。
ところで、チップレットはどちらかというと自社の設計資産を活かして、開発期間を短縮し、歩留まりを確保する手段であった。これに対して、他社の設計資産・チップ資産を活用して開発コストを下げる動きが出てきた。これを実現するためには、インターフェイスを標準化する必要がある。チップレットを標準化する活動に取り組んでいるのが、2022年3月に発足したUCIe(Universal Chiplet Interconnect Express)である。Intelが中心となり、NVIDIA,AMD,arm,Samsung,Qualcomm,TSMC,ASE,Google,Meta,Microsoft,Alibabaがボードメンバーとして参画している。Advanced-PKG(UCIe-A:伝送距離2mm以下)では、データ速度は4Gbps~32Gbps,バンプピッチは25~55μm(高速ほど広い)との規格が定まりつつある。
3. HBMが牽引する3D実装技術の進化
3D実装としては、DRAMチップを縦積みしたHBM(High Bandwidth Memory)が有名である。最初の標準化は2013年であり、SK-Hynixが主に生産していたが、コスト高のため採用は高級機に限られていた。ところが、生成AIの生産のボトルネックがGPUチップよりHBMであることが判明し、急に注目(高利益率)され、DRAMメーカー各社の本格参入と増産が行われている。DRAMを2次元的に実装したDDRに比べると、データ幅が1024bitと大きく、10倍以上のメモリ帯域幅を実現することができる。ちなみにDDRのデータ幅は64bitである。まさに3D実装した効果である。
最新の規格HBM3Eでは12チップ積層し、総メモリ容量は32GB,データ転送速度は1.2TB/sである。各信号線(ピン)当たりの伝送速度は8Gbpsである。次世代のHBM4(2026年予定)は16チップ積層,メモリ容量48GB,メモリ帯域幅2,048bit,データ転送速度1.5TB/s以上を予定している。
先に見たように、GPUとHBMはインターポーザ上で2.5D実装される。GPUとHBMを積層すれば、さらに性能向上が図れると考えるのは自然な発想である。2023年に東京工業大学(現東京科学大学)はGPUの上にキャッシュメモリやDRAM(HBM)を積層する技術BBCube 3D(Bumpless Build Cube 3D)を開発したと発表した。実装面積を小型化でき、メモリ帯域幅を上げるだけでなく、消費電力をHBM2Eに対して1/5まで削減できるという。
イメージセンサも早くから3D実装を採用してきた。光電変換数する画素部とロジック回路を、それぞれの最適なプロセスで製造した後に積層する。例えば、高い電圧が必要な画素部は90nm技術、高速の信号処理が必要なロジック部は40nmプロセスを利用するといった具合である。イメージセンサの最大手であるソニーは2012年から3D実装を採用した製品を上市している。
3D実装のキー技術はSi貫通電極TSV(Through Si Via)である。作り方はいくつかの方法があるが、例えば、回路製造まで終了したSiウェハを薄層化して、裏面から貫通孔を開けて、そこに電極を埋め込むことで実現できる。ウェハの接続にはバンプやウェハ貼り合わせ技術を用いる。
4. 光I/OとCPOが切り拓くヘテロジニアス集積
2.5D/3D実装の先にあるのがヘテロジニアス実装であると言われている。例えば、ロジックデバイスとメモリ,高周波IC(MMIC),光デバイス(レーザー,Siフォトニクス),MEMSセンサなどを用途に応じて集積化する技術である。
その中で注目されているのがSiフォトニクス(PIC)をGPUと集積化する技術である。GPUの外部との接続容量(帯域幅)は拡大を続けており、電気配線での接続は限界に達すると言われている。いわゆる光I/Oを有するGPUであり、CPO(Co-Packaged Optics)あるいは光電融合技術と呼ばれているものである。先に述べたチップレットの標準化団体UCIeの中で標準化が進められている。光導波路や合分波器,光フィルタ,光変調器,フォトダイオードなどが集積されたPICと、ドライバICやTIAアンプ,イコライザーやクロック/データ再生回路などが集積されたEICを積層(3D)実装して、光エンジンと呼ばれる光I/O回路を形成する。これをHBMと同じようにインターポーザ上にGPUチップと共に2.5D実装する。なお、半導体レーザーチップをPIC上に積層集積する技術の開発も進められている。
電気I/Oではバンプ出力で済むが、光I/Oでは光ファイバなどの外部光導波路に接続する必要がある。光ファイバと光部品の接続では、結合効率を最大化するために計測しながら光軸合わせを行うアクティブ接続が使われてきた。しかし、ファイバの本数が多くなる中で、かつ実装コストを下げるためには、計測を伴わないパッシブ実装が求められる。レンズ系を用いて合わせマージンを拡げる、あるいはガラスやポリマー光導波を介在させるなどの手法が検討されている。
TSMCは、やや異なったアプローチを採用した多くの特許を出願している。それは再配線(RDL)技術をベースとするもので、電気の再配線と同様に光の再配線(光導波路)を作り込んでいこうとする技術である。かなりのリソースを割いて開発を進めているようであるが、未だに実体は公開されていない。
光I/Oに関しては、多くの技術が検討されている状況であり、エコシステムの構築も含めた標準化が必要であろう。2020年代の後半には製品化が進むと想定されている。
5. 生成AIが加速する半導体実装技術の未来
実装技術は半導体技術と共に進歩してきた。集積回路とは実装技術をウェハプロセスに取り込んで実現した技術であるとも言える。2.5D/3D実装は、ウェハプロセスを実装に拡張した技術であるとの捉え方もできる。また、いろいろな意味で物理限界に達しようとしている集積回路技術の壁をブレイクする技術である考えることもできる。TSMCやIntelなどの最先端LSIメーカー大手がこれまで以上に実装技術に取り組んでいるには、このような背景があるためである。
久々に日本で最先端LSIを量産化しようとするラピダスの活動が本格化しようとしている。ラピダスは実装まで含めた一貫製造を行うと宣言し、それに対する日本政府の支援を得ることにも成功している。2025年2Qには千歳のセイコーエプソン工場に3D実装工程のパイロットラインの構築を進める計画である。生成AIの爆発的に増大するパラメータに対応できるのは3D実装しかないと言い切れる日も近いと考えている。
株式会社英知継承では、本テーマに関して当該専門家による技術コンサルティング(技術支援・技術調査)が可能です。下記よりお気軽にお問い合わせください。
▼「電気電子・光通信」に関連する技術解説一覧
Co-Packaged Optics(CPO)とフォトニック集積回路(PIC)
テラヘルツ波の光ファイバ無線技術(テラヘルツ・オーバー・ファイバ)
直流給電(DC給電)はZEHを加速するか? 住宅DC化の最新動向と課題
量子センサとは何か ― 原理・種類・応用から実用化動向まで ―
DRAMとSSDのギャップを埋める高速不揮発性メモリの最新動向
自動運転を支える車載E/Eアーキテクチャと車載ネットワークの最新動向