- HOME >
- 専門家による技術解説 >
- 生成AI時代に注目されるディスアグリゲーテッドコンピューティング
生成AI時代に注目されるディスアグリゲーテッドコンピューティング
2025.04.09
生成AI時代に注目されるディスアグリゲーテッドコンピューティング
― AIデータセンターを変える次世代アーキテクチャとは ―
1. 生成AIが突きつけるAIデータセンターの限界
データセンターはサーバの塊である。サーバは、主にCPU(Central Processing Uni)を中心に、行列などの並列計算が得意でアクセラレータとして働くGPU(Graphics Processing Unit、最近は画像処理だけでないのでGP(General-purpose)GPUと呼ばれる)、及び高速メインメモリDRAM(Dynamic Random Access Memory)と大規模ストレージSSD(Solid State Drive)といったメモリで構成され、これらの構成要素が電気ネットワークで相互に接続されている。一つのサーバで処理できないジョブは、サーバに搭載されているNIC(Network Interface Card)と、外部のスイッチなどを含む高速LAN(Ethernet)で他のサーバと接続して、計算能力を高めて対応する。
この従来のコンピューティングアーキテクチャでは、巨大化する一方の生成AIに対応できなくなると言われている。生成AIはパラメータ数を大きくすればするほど正答率が高まる、つまり「お利口になる」とのスケーリング則がある。パラメータ数は2年で240倍の割合で増え続けているとの報告もある。必要とされる計算能力とメモリ容量もほぼパラメータ数に比例する。GPUの処理の能力は2年で3.1倍、GPUに搭載される高速DRAM(HBM:High Bandwidth Memory)は2年で2倍の増大率に過ぎない。そのため、サーバつまりGPU数を増やして並列度を上げることで対応するしか方法はない。現在ハイパースケーラのAIデータセンターには1万台程度のGPUサーバが設置され、相互に接続されている。10万台を接続するAIデータセンターの構築もスタートしている。さらに、2025年1月21日にソフトバンクやOpenAIなどによって発表されたスターゲート・プロジェクトでは、向こう4年で$500Bの巨額資金を投入して、数百万台ものGPUを含む巨大なAIデータセンター(おそらく複数)を構築するという。現在の延長線上のコンピューティングアーキテクチャでは対応できないのではないかと思われる。
それを解決する有力な候補となるのが、ディスアグリゲーテッドコンピューティングアーキテクチャである。単純には、CPUやGPU、DRAM、SSDの構成要素ごとにまとめるとともに、光I/O(インタフェース)を持たせ、高速・低遅延の光インターコネクトで接続するものである。DRAMやSSDをCPUやGPUでシェアすることで、計算リソースを有効に使うことができる。また、ジョブによって、計算リソースの組合せを光インターコネクト内の光スイッチにより最適化することで、性質の異なるジョブにも柔軟に対応できる。また、現在生成AIをターゲットにアーキテクチャを最適化しているが、それより優れたAIアルゴリズムが将来登場すると考える方が自然である。当然コンピューティングアーキテクチャも変える必要がある。ディスアグリゲーテッドであれば、柔軟にアルゴリズムの革新に対応でき、巨大な投資が無駄にならずに済む。
以下、簡単に従来アーキテクチャとディスアグリゲーテッドアーキテクチャを概説していきたい。
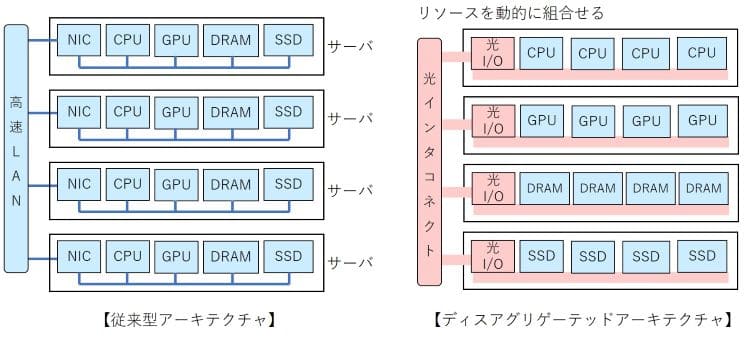
図. ディスアグリゲーテッドコンピューティング
2. GPU中心で進化した従来型アーキテクチャ
生成AIでは、CPU中心のアーキテクチャからGPU中心のアーキテクチャになっている。例えば、NVIDIAのGPU-H100のシステムを簡単に説明しよう。GPUのパッケージにはDRAMを3次元に実装したHBMが5台(メモリ容量80GB)搭載されている。GPUとHBMはSiインターポーザを用いた高密度配線により、3.352TB/sの帯域幅で接続される。1つのサーバに搭載された8基のGPUが4基の広帯域幅低遅延スイッチで相互に接続され、あたかも1基のGPUのように動作する。サーバ内には2基のCPUおよび8基のNICも搭載されている。1台のサーバには他のサーバ等との接続のために、22基の800Gbps光トランシーバが装着できるようになっている。一つのラックにはこのようなサーバが4台搭載され、ラック内およびラック間のサーバが800Gbpsの光トランシーバと25.6Tbpsの大容量電気スイッチでノンブロッキングに相互接続されている。
例えば、5,120基のGPUから構成される同社EOSでは、Leaf、Spine、Coreの3段のスイッチアーキテクチャで、それぞれ、160基、160基、80基のスイッチを擁している。なお、アクセス時間がさほど気にならないSSDはまとめられて、別のラックに搭載されている。
もちろんこれは基本型であり、導入されているMicrosoftやGoogleなどのデータセンターでは独自の相互接続アーキテクチャを有しているようである。ただし、GPU+HBMやCPUを含むサーバを単位とするところは変わらない。
Googleでは、ディスアグリゲーテッドアーキテクチャに繋がる光スイッチを用いたアーキテクチャを採用している。下層のLeafスイッチは大規模電気スイッチであるが、それらを接続するSpineスイッチを光スイッチに替えている。電気スイッチがパケットごとにスイッチングできるのに対して、光スイッチはパケットのアドレス情報を見ることができず、一定時間は相互接続するポートを固定する回線交換型のスイッチであり、OCS(Optical Circuit Switch)と呼ばれている。スイッチング機能に制約はあるものの、光スイッチは安価で低消費電力であることから、データセンターの設備投資を約30%削減、また消費電力を約40%削減できるという。データセンター内の設備の拡張にも柔軟に対応することができるというメリットもある。
3. メモリの壁を超えるディスアグリゲーテッドコンピューティング
生成AIのパラメータ数は2年で240倍の割合で増え続けているのに対して、GPUに搭載されるDRAM(HBM)は2年で2倍の増大率に過ぎない。これは「メモリの壁」と通称されている。メモリプールあるいは共有メモリを通信で接続すれば解決できるはずであるが、通信(インターコネクト)の帯域幅は2年で1.4倍というさらに緩やかなペースでしか伸びていない。これでは通信がボトルネックになる。つまり、ディスアグリゲーテッドアーキテクチャを実現するには、ます相互接続する通信から見直す必要がある。
これに対応するため、CXL(Compute Express Link)の標準化がIntelなどによって進められている。サーバ内のCPUとDRAMを接続している短距離のインターコネクトであるPCIe(PCI Express)の距離を20-30mまで伸ばして接続しようとのコンセプトである。通信のオーバヘッドやエラー訂正などが簡略化されて、通信レイテンシー(遅延)は200ns程度まで短縮化できる。CXLを使用することで、2.5倍のメモリへのアクセスがCPU負荷15%増で達成できるとの試算もある。部分的なディスアグリゲーテッドアーキテクチャである。CXLの市場は今後急増すると期待されており、2026年には$2.1B、そして2028年には$15.8Bになるとの市場予測もある。
これ以外にもディスアグリゲーテッドアーキテクチャはいくつか検討されている。以下に説明するのは、光電融合技術を前提としたアーキテクチャである。
ディスアグリゲーテッドアーキテクチャでは、CPUやGPUあるいはDRAMのインターフェースを光I/Oにすることが好ましい。CPU-NIC-光トランシーバ-光ファイバーという現在の接続形態より、CPU(with 光I/O)-光ファイバーといった接続形態の方が消費電力を削減し、伝送帯域幅を拡幅し、伝送遅延(レイテンシー)も短縮できる。離れた位置にCPU、GPUやDRAMを置く以上、その接続インターフェースもそれに見合った形にすべきである。いわゆる光電融合技術の採用である。
光ファイバーの伝送遅延は5ns/mであるから、遅延を100ns以下にするには、20m程度の範囲に留めたい。この範囲の複数のラック内にGPU、CPU、DRAM、SSDを適宜配置して相互接続する。光スイッチで接続することが好ましいが、パケット単位のスイッチングができないので、光I/Oを持つ低遅延電気スイッチを用いる、あるいは光スイッチ(OCS)とのハイブリッド接続となる。
この20m範囲のディスアグリゲーテッドコンピュータを1単位とし、それを光I/OのLealスイッチおよびSpine光スイッチ(OCS)で多段に相互接続する。ジョブごとの計算リソースの組合せの変更や設備の拡張、あるいはAIアルゴリズムの変更はOCSで対応するといった形が想像される。
4. 生成AIの将来とディスアグリゲーテッドコンピューティングの展望
生成AIの爆発的な成長需要に応えるため、コンピューティングハードウェア、ソフトウェアおよびアーキテクチャの革新が求められている。ディスアグリゲーテッドアーキテクチャもその一つであり、当面の解として、OCSやCXLがあり、将来的には光I/Oあるいは光電融合技術を用いたシステムがある。AIブームの最大の課題(リスク)は生成AIの基盤をなすTransformerアルゴリズムがどこまで続くかということではないかと思われる。アルゴリズムが変わるとコンピューティングリソースの比率や接続形態も変わってくる。GPU中心でなく、メモリ中心のアルゴリズムも、より人間の脳に近いシステムとして考えられている。このようなアルゴリズムの変更にも柔軟に対応できるのが、ディスアグリゲーテッドの良いところである。いずれにしろ、生成AIの将来と関係して、ディスアグリゲーテッドコンピューティングの開発動向についても、ウォッチングしていく必要がある。
株式会社英知継承では、本テーマに関して当該専門家による技術コンサルティング(技術支援・技術調査)が可能です。下記よりお気軽にお問い合わせください。
▼「電気電子・光通信」に関連する技術解説一覧
Co-Packaged Optics(CPO)とフォトニック集積回路(PIC)
ダイヤモンド半導体はSiC・GaNを超えるか? 究極のパワー半導体材料
テラヘルツ通信を支えるTHz-over-Fiberの仕組みと応用
直流給電(DC給電)はZEHを加速するか? 住宅DC化の最新動向と課題
量子センサとは何か ― 原理・種類・応用から実用化動向まで ―
DRAMとSSDのギャップを埋める高速不揮発性メモリの最新動向