- HOME >
- 専門家による技術解説 >
- ニューラルネットワークとAIチップの進化
ニューラルネットワークとAIチップの進化
2022.03.21
ニューラルネットワークとAIチップの進化
― エッジAIからニューロモーフィックまで ―
1. AIとニューラルネットワークの基礎構造
AIとほぼ同義語になったニューラルネットワークは、画像認識や音声認識、自然言語処理、自動運転、信号解析、ビッグデータ解析、ゲームなどあらゆる分野に応用されつつある。
ニューラルネットワークの新しいモデルが年々更新され、多くのオープンソースが流通し、専用AIチップ開発のベンチャーが次々と生まれている動きの激しい混沌とした世界である。
AIの応用分野は大きく「予測」「分類」「実行」の3つに分けることができる。予測は、過去のデータを学習することで、未来あるいは異なる条件での結果を予測する技術である。需要予測やECのお勧め表示などがあり、最も実用化が進んでいる。分類には、画像認証や音声認識などがあり、ディープラーニングの登場によって近年急速に発達し、その精度が著しく向上している分野である。実行は、車両の自動運転や機械翻訳、ゲーム攻略といった成果の分かりやすさとインパクトの強さから、一般の人がイメージするAIの分野である。社会的に受け入れられるには技術以外の「倫理」といった要素もあり、多面的な開発が求められている。
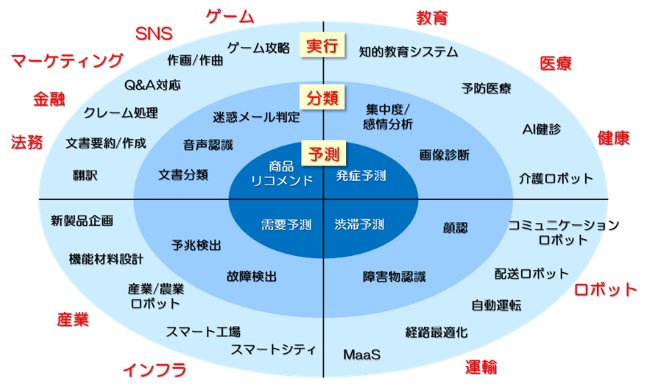
図1. AI技術機能の進歩と応用
AIは専門家でなくとも利用できる環境の整備された技術といえる。利用頻度の高いプログラムをまとめて、一部を修正するだけで利用できるようにした「ひな形」であるTensorFlowなどのフレームワークが公開され、AI開発参入への障壁を下げている。なお、Google系と反Google系の主導権争いもある。
AIは「学習」と「推論」の2つのプロセスからなる。学習とは入力されたデータを分析することによりコンピュータが識別等を行うためのパターンを確立するプロセスで、この確立されたパターンを学習済みモデルという。推論とは、学習済みモデルに実データを入力し、確立されたパターンに従って実際にそのデータの識別等を行うプロセスである。推論はエッジなど限られた計算リソースでの高速処理が求められる。推論系に最適化されたフレームワークへの変換や最適化のためのコンパイラも整備されつつある。自社AIチップへの最適化コンパイラも公開されている。
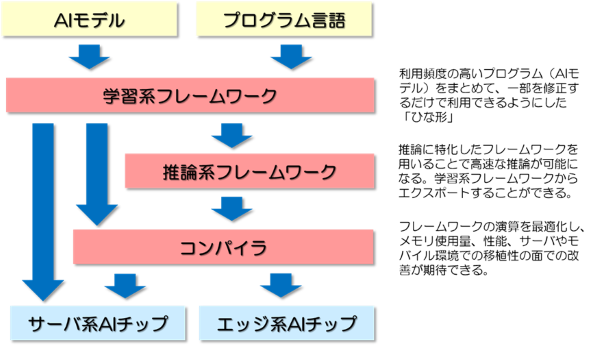
図2. AI開発環境(モデル~ソフトウェア~ハードウェア)
2. CNN・RNN・Transformerの原理と応用分野
ニューラルネットワークは、人間の神経細胞のネットワークを模したモデルで、入力層、中間層(隠れ層)および出力層のニューロンとそれらを接続するシナプスから構成される。機械学習とは接続の仕方とその重み付けを多数のデータを基に自動的に構築することである。
深層学習(ディープラーニング)とは、多層の中間層を有するニューラルネットワークを用いて行う機械学習のことをいう。深層学習により、コンピュータがパターンやルールを発見する上で何に着目するかとの特徴量を自ら抽出することが可能となり、何に着目するかをあらかじめ人が設定していない場合でも識別等が可能になり、現在のAIブームをもたらした。画像認識にはCNN(Convolution Neural Network)、音声認識にはRNN(Recurrent Neural Network)、自然言語処理にはTransformerと応用によってそれに適したモデルが細分化されている。応用の垣根を越えてモデルが統合される可能性もあるし、次々と新しいモデルがそれぞれの応用に開発される可能性もある。とにかく進歩の激しい領域である。
DNNの隠れ層は畳み込み層とプーリング層で構成される。畳み込み層は、前の層で近くにある複数のノードにフィルタ処理して特徴マップを得る。プーリング層は、畳込み層から出力された特徴マップをさらに縮小して新たな特徴マップとする。画像の特徴を維持しながら画像の持つ情報量を大幅に圧縮できる。2012年の画像認識コンペILSVRCで圧倒的な成績で優勝しディープラーニングブームの火付け役となったAlexNetは8層構成である。その後改良が進められた到達点がResNetで152層から構成される。ただし、処理ブロックをショートカットするResidualモジュールを導入することで、多層でも効率的な学習が進むようにしている。
自己フィードバックを有する再帰的ネットワークRNNは、音声波形、動画、文書(単語列)など時系列のデータを取り扱うことに適したニューラルネットワークである。例えば、音声という可変長の時系列データをニューラルネットワークで取り扱うため、隠れ層の値を再び隠れ層に入力する。長時間前のデータを利用しようとすると演算量が爆発するなどの問題があったが、その欠点を解決したのがLSTM(Long Short-Term Memory)というアルゴリズムで、自然言語処理に応用されている。
自然言語処理ではRNNでもCNNでもないディープラーニングであるTransformerの進歩が著しい。Attention(文中の単語のどれに注目すれば良いかを表すスコア)のみを使用 したEncoder-Decoderモデルで、並列化が可能であるため、学習時間が短縮される。BERT、GPT-2、T5などと次々に改良され、人間の能力を超えたとまで言われている。Transformerはその応用範囲を広げている。CNNを組み合わせたモデルであるConformerは音声認識に応用され、RNNを超える最高の精度を達成している。長い時間的依存関係を抽出するのを得意とするTransformerと局所的な関係を抽出するのが得意なCNNを組み合わせたものである。画像認識に適用する画像認識モデルVision Transformerも提案されており、CNNより計算リソースが少なくて済むという。
3. AIチップの基本構造 ― 積和演算アクセラレータ ―
ニューラルネットワークの信号処理は、形式ニューロンの持つ値に重みを乗算した値を足し合わせたものと同じである。AIチップは、この積和演算を高速に実現する(高速積和アクセラレータ)ことで脳の動作を模倣する。AI演算用タイルを必要な数だけ敷き詰めるのが最近主流の構成である。例えば、エンドポイントのセンサ制御では1個、中規模のエッジ処理では4-16個程度、データセンターなどのサーバでは64個以上のタイルを敷き詰める。
AIチップの機能は推論用と学習用に大別される。どちらも高速な積和演算が必要なことは同じだが、推論に比べて学習は膨大な数の積和演算を実行する必要がある。例えば、Googleは自社のデータセンター用AIチップとしてTPUを開発している。初代(2017年)は8ビット固定小数点演算で推論用にしか使えなかったが、第2世代から16ビット浮動小数点演算にし、学習への適用も可能とした。第3世代の性能が120Tops@250Wであり、最新の第4世代はその2.7倍の性能といったように高性能化が進んでいる。第4世代は基板に4個TPUを搭載し液体冷却する。このボードをキャビネットに多数枚搭載し、さらに多数のキャビネットを高速伝送線路で接続するといった構成になっている。
推論用のAIチップは小型・低消費電力で、なおかつリアルタイムの処理が求められる。例えば、Gyrfalco社はUSBメモリのような形状のAIスティックを販売している。それを構成しているマトリックス処理エンジンであるAIチップは、PIM(Processor In Memory)技術を使用してニューラルネットワークモデルの計算処理を行う。PIMはメモリ回路内でメモリデータの読み出し中に積和演算を行うニューラルネットワークに適したアーキテクチャで、メモリと演算回路間のデータ伝送(データアクセス)に伴う消費電力の増大を抑制している。このAIチップは約2万8000ノードと10Mバイトのメモリを備え、一般的なモデルに必要な性能を全てチップに盛り込むことができるとされている。
4. アナログ演算と磁性デバイスの可能性
AIチップ開発には、IntelやNvidiaなどの既存の大手半導体ベンダー、ARMなどのIPベンダーに加え、GAFAMやIBMといったビックテック、それに欧米中の多くのスターアップが参入する、正に戦国時代の様相を呈している。
高性能化の開発スピードも速く、消費電力当たりの処理能力は2.5年で10倍のペースで増えている。例えば5nmプロセスを用いたHuaweiのKirinは36Tops/Wを達成している。CPU→GPU→ASICの順で性能が良くなる。FPGAはGPU並の消費電力当たりの処理能力であるが、GPUより低消費電力である。
消費電力に余裕のある車載用エッジデバイスでは目標とする性能に近づいているが、低消費電力に対する要求の強いモバイル用途では、1桁以上の性能向上が求められている。特にエッジデバイスでは精度よりも性能と低消費電力が求められることから、計算の精度を32ビットから8ビットに落とすことが行われている。
2値(1ビット)でも処理できないかとのBNN(Binary Neural Network)の検討も行われている。あるいは積和処理はアナログでも良いのではとの検討も進んでいる。この延長線上に磁性デバイスを用いたニューラルネットワークの検討がある。
5. 磁性デバイスが拓くインメモリAIとニューロモーフィック技術
一つのデバイスで記憶、演算(重み加算)および学習機能といったニューラルコンピュータに必要な機能を実現できれば、AIチップの性能を飛躍的に向上させることができるはずである。上記のPIMを発展させたインメモリ・コンピューティングと呼ばれている。デバイスの候補としてReRAM(抵抗変化メモリ)、PCM(相変化メモリ)やMRAM(磁気抵抗メモリ)などの不揮発性メモリがあげられている。ワード線とビット線の交点にマトリックス状に配置した不揮発性メモリの抵抗(シナプスに相当)を学習により変化させることで、アナログ・ニューラルネットワークを構築することができる。
Samsungは2022年1月にMRAMベースのインメモリ・コンピューティングを発表した。STT-MRAM(スピン注入型磁化反転磁気抵抗メモリ)は抵抗が小さいために積和演算による電流合算方式では消費電力が大きくなってしまうとの問題があった。これを抵抗合算方式に替えて消費電力を削減する工夫をしている。64×64のクロスバーレイアウトのものを試作している。
同社はこのデバイスをニューロモーフィックに展開しようとしている。ニューロモーフィックは人間の脳のネットワークをできるだけ充実に模倣した非ノイマン型アーキテクチャで、IBMのTrueNorthが有名である。例えば人間の脳を高感度で実測し、半導体(ニューロモーフィック)にコピー&ペーストして脳をエミュレートすることができるようになるという。ハーバード大学と共同でこの研究を進めている、FSの世界を現実のものにするといった壮大な構想である。なお、人間の脳は100兆個(100T個)以上のシナプスがあると言われており、まだまだ実現は先になると思われる。
リザバー・コンピューティングも磁性デバイスの新たなニューラルネットワークへの応用分野と言える。これは入力層と、ランダムな相互結合したリザバー(溜池)層と、出力層の3層から構成される一種の再帰的ニューラルネットワーク(RNN)である。通常のRNNと異なり、リザバー層の相互結合は学習の対象とならない固定のネットワークで構成され、出力へ向かう接続の重みのみを学習で調整する。シンプルな構成とシンプルな学習アルゴリズムのために低消費電力性に優れると期待されている。処理が軽いため、エッジデバイスでありながらオンライン学習も可能である。入力データを非線形変換によってリザバー層の高次空間に写像して、線形分離の可能性を高めるというコンセプトである。そのためのリザバー層はランダムで高次元な接続を持つものであれば何でもよく、デバイスに備わった固有の物理特性を利用することもできる。具体的には、スピントルク発振素子やスピン波を用いる検討がなされている。
6. ニューラルネットワークの課題とビジネス機会
ニューラルコンピュータは、AIブームの基盤となっている技術で、材料からデバイス、ハードウェア、ソフトウェア、応用に至るまで、多くの企業・機関が参加し急速に進歩している技術領域である。また、オープンなフレームワークなども充実しており、参入障壁が低く、特に応用する立場からは道具立てがそろっている。
本稿では触れなかったが、最大の障壁は大量に必要になる学習データの収集かもしれない。プライバシーなどの問題もあり分野によってはデータ収集が困難な領域もある。あるいは故障の予兆や不良解析のように、不良・不具合のデータがそもそも不足している応用領域もある。また、帰納的に答えを出すシステムであるため、理性に訴える演繹的手法と違って納得感が乏しいといった不満も残る。ニューラルネットワークで得られた結論の正しさをどこまで信じればよいのか、大概は正しいのだけれどもレアな「この」ケースにどこまで適用できるのか、等々の疑問は残る。計算リソース不足から、そもそもリアルタイムで分析できないといった対象もある。
しかし、走り始めたこの道はゴールまで到達する勢いがある。上記のような疑問を解消するには、まだまだ技術革新が必要で、全ての技術領域にビジネスチャンスがあると言い換えることもできる。まずは、ブームに惑わされることなく、冷静に状況を分析することが必要であろう。
株式会社英知継承では、本テーマに関して当該専門家による技術コンサルティング(技術支援・技術調査)が可能です。下記よりお気軽にお問い合わせください。
▼「電気電子・光通信」に関連する技術解説一覧
Co-Packaged Optics(CPO)とフォトニック集積回路(PIC)
ダイヤモンド半導体はSiC・GaNを超えるか? 究極のパワー半導体材料
テラヘルツ通信を支えるTHz-over-Fiberの仕組みと応用
直流給電(DC給電)はZEHを加速するか? 住宅DC化の最新動向と課題
量子センサとは何か ― 原理・種類・応用から実用化動向まで ―
DRAMとSSDのギャップを埋める高速不揮発性メモリの最新動向
自動運転を支える車載E/Eアーキテクチャと車載ネットワークの最新動向